什么是 ollama?
为什么选择 ollama?
- 能直接运行大模型,与大模型进行对话。
- ollama 命令具有管理大模型的能力。
- 利用 cpu 运行大模型。
- 本地大模型安全可靠。
- 终端直接开始聊天。
- 社区提供了支持 web api 方式访问 WebUI。
如果你还没有尝试过在本地部署过大模型,那么 ollama 非常适合你。建议搭配WebUI一起使用
准备工作
- docker 为了方便部署软件。
- 存储空间充足的机器,一般来说参数越大,需要配置越好。
- 良好的网络环境。
安装 ollama
进入 ollama 下载页面,选择自己的系统版本的下载并安装即可。
检验是否安装成功
输入 Ollama 命令,正常的得出命令行输出,表示已经安装成功,下面有 ollama 的常用命令:
代码登录后可见
ollama 模型库
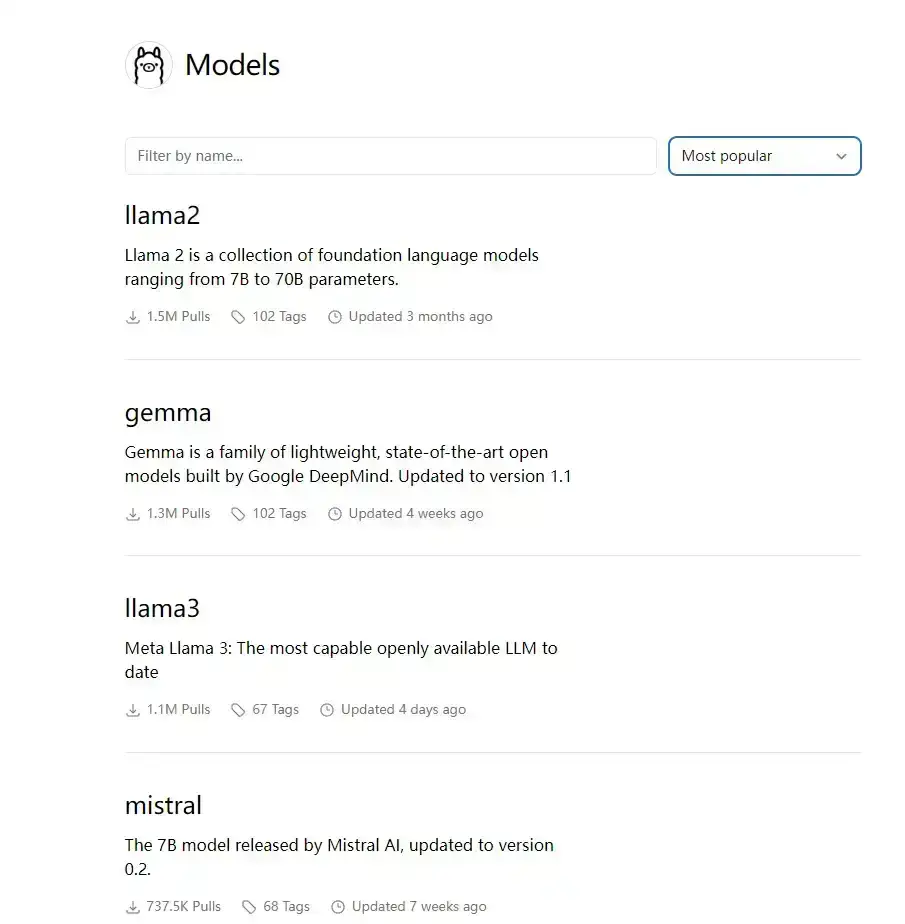
我们可以在 [链接登录后可见] 中搜索已有我们想要的模型库。以下是一些流行的模型:
| 模型 | 参数 | 尺寸 | 执行下载 |
|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
这里大概列出了 代码登录后可见、代码登录后可见 以及 代码登录后可见 我们景见的模型以及参数以及尺寸大小。由图表可以看出 Gemma 2B 模型的尺寸还是比较小的,初学者入门。
运行模型
代码登录后可见
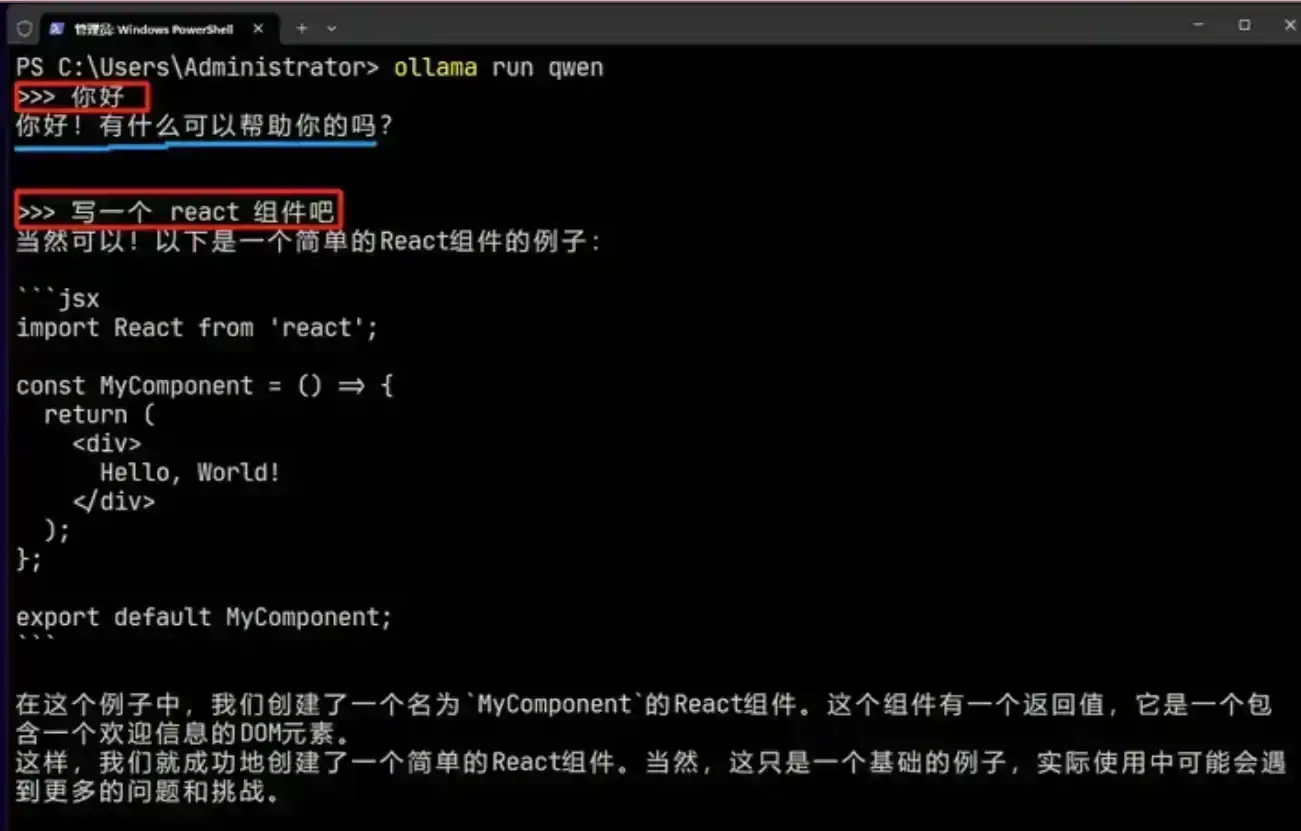
因为qwen 模型对中文支持比较好,这里使用 qwen 模型进行聊天
直接使用 run 命令 + 模型名字就可以运行模型。如果之前没有下载过,那么会自动下载。下载完毕之后可以在终端中直接进行对话 qwen 模型了。
直接在终端中对话:用 ollama 千问模型写一个 React 组件
使用 api 方式运行
代码登录后可见
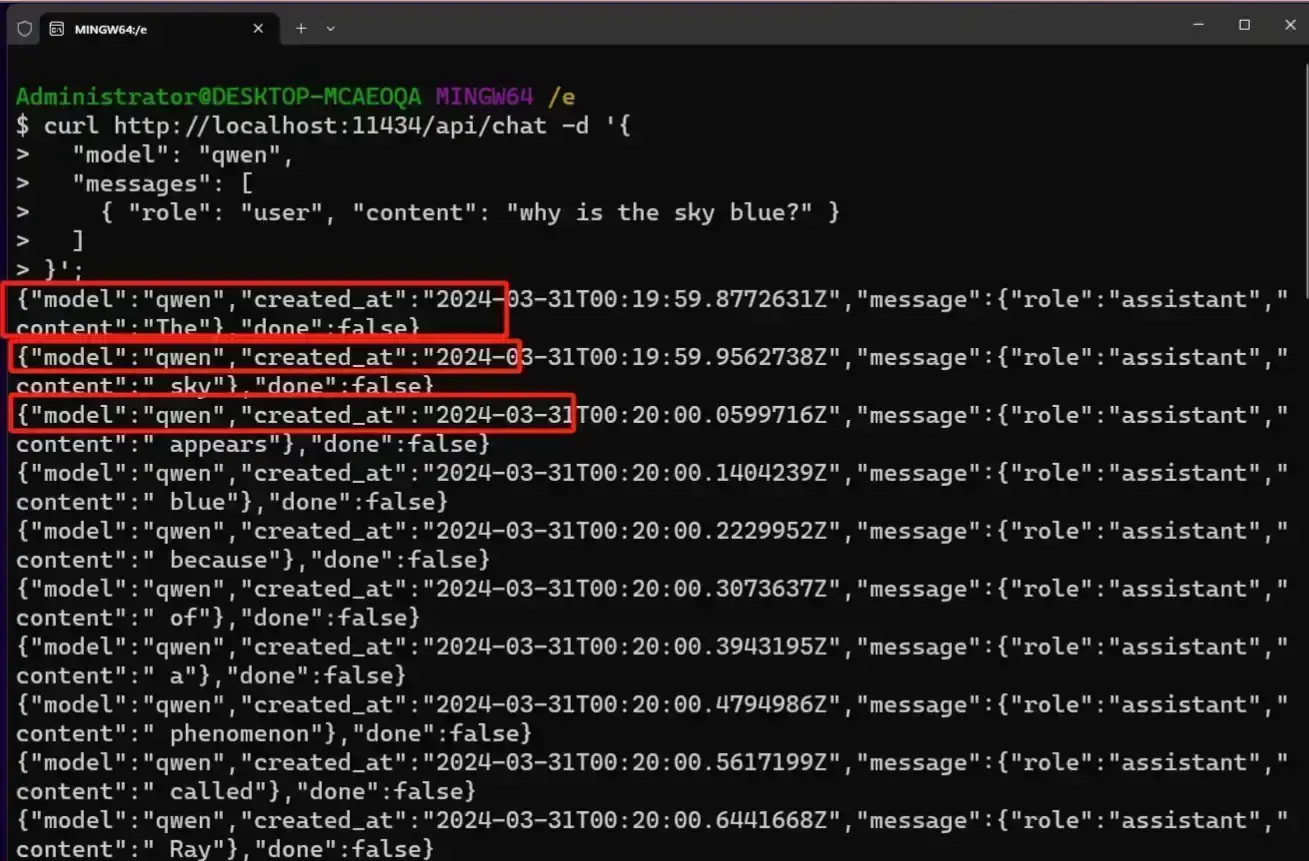
api 访问的方式:模型在不断推送字段。我们需要自己处理。
推荐 Open WebUI
LLMs用户友好的WebUI(以前的Ollama WebUI)
相关安装文章 [链接登录后可见]
使用 docker 可以方便的部署
代码登录后可见
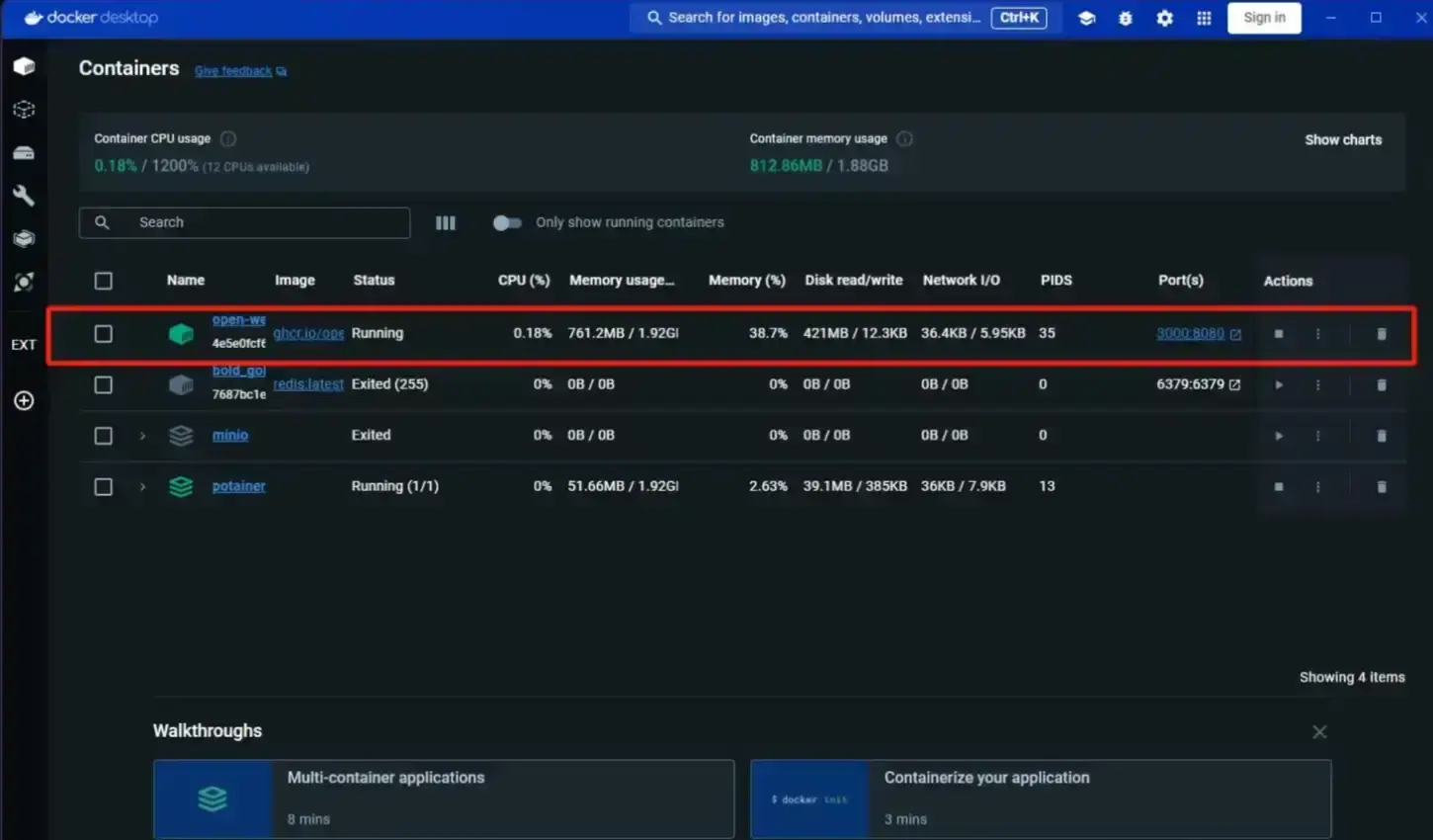
注意 代码登录后可见 时长被其他的开发程序占用,使用需要注意自己的端口是否被占用。
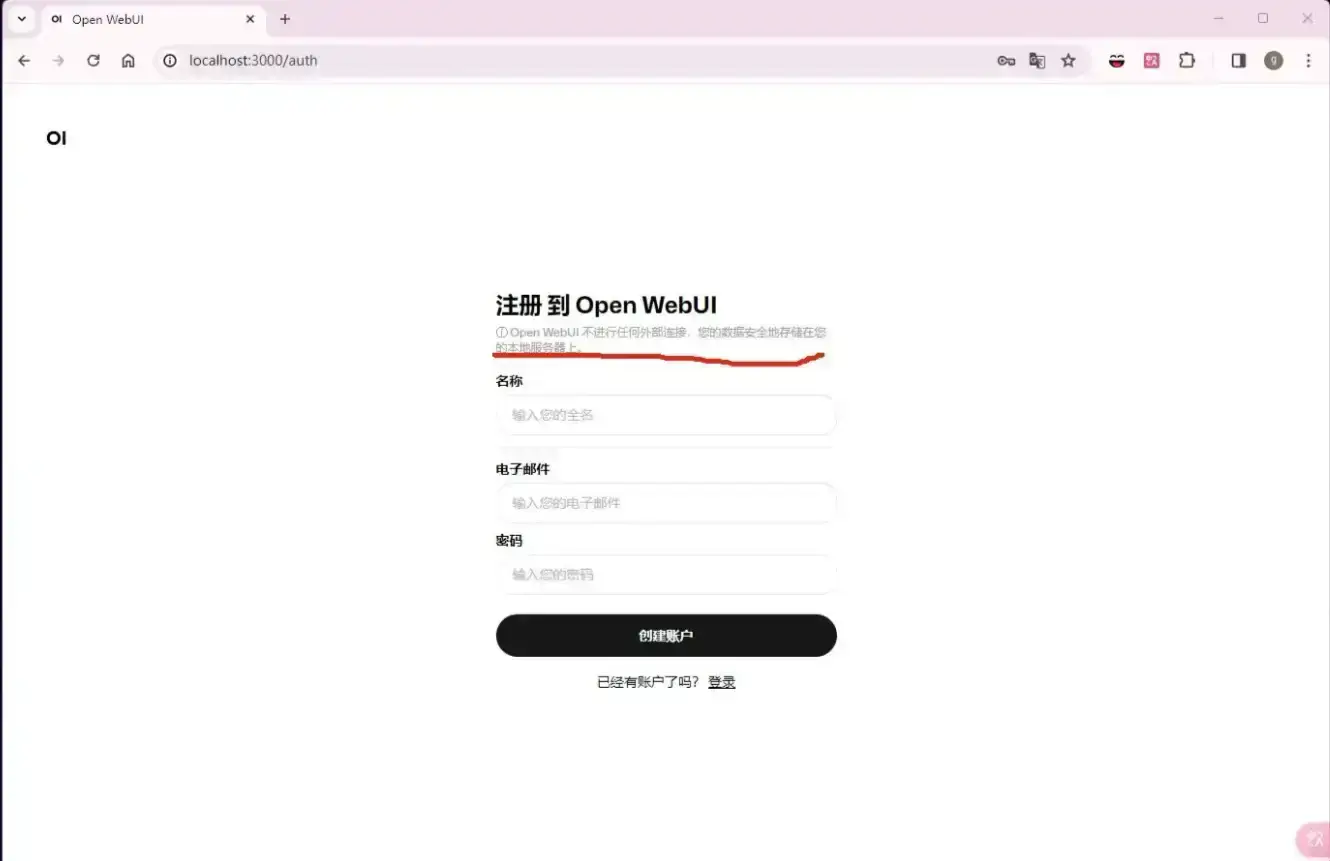
注册
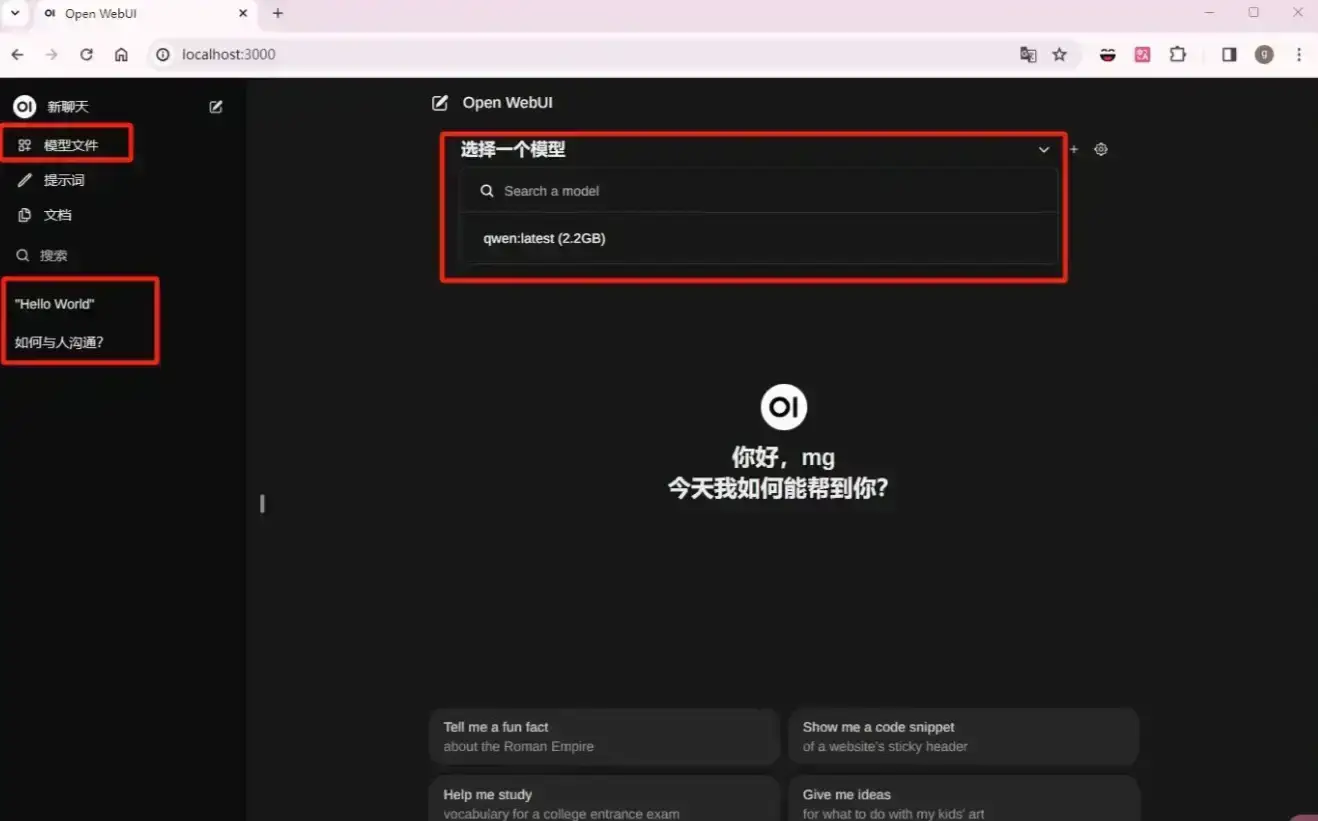
Open WebUI 聊天界面
反向代理
参考教程:[链接登录后可见]
⚠️Nginx Proxy Manager(以下简称NPM)会用到80、443端口,所以本机不能占用(比如原来就有Nginx)
互联网使用请确保完成了域名解析