
项目地址:[链接登录后可见]
Langchain-Chatchat 是什么
Langchain-Chatchat基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
本项目利用 langchain 思想实现的基于本地知识库的问答应用,目前langchain可以说是开发LLM应用的首选框架,而本项目的目标就是建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。

实现原理
本项目全流程使用开源模型来实现本地知识库问答应用,最新版本中通过使用 FastChat 接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型,依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。
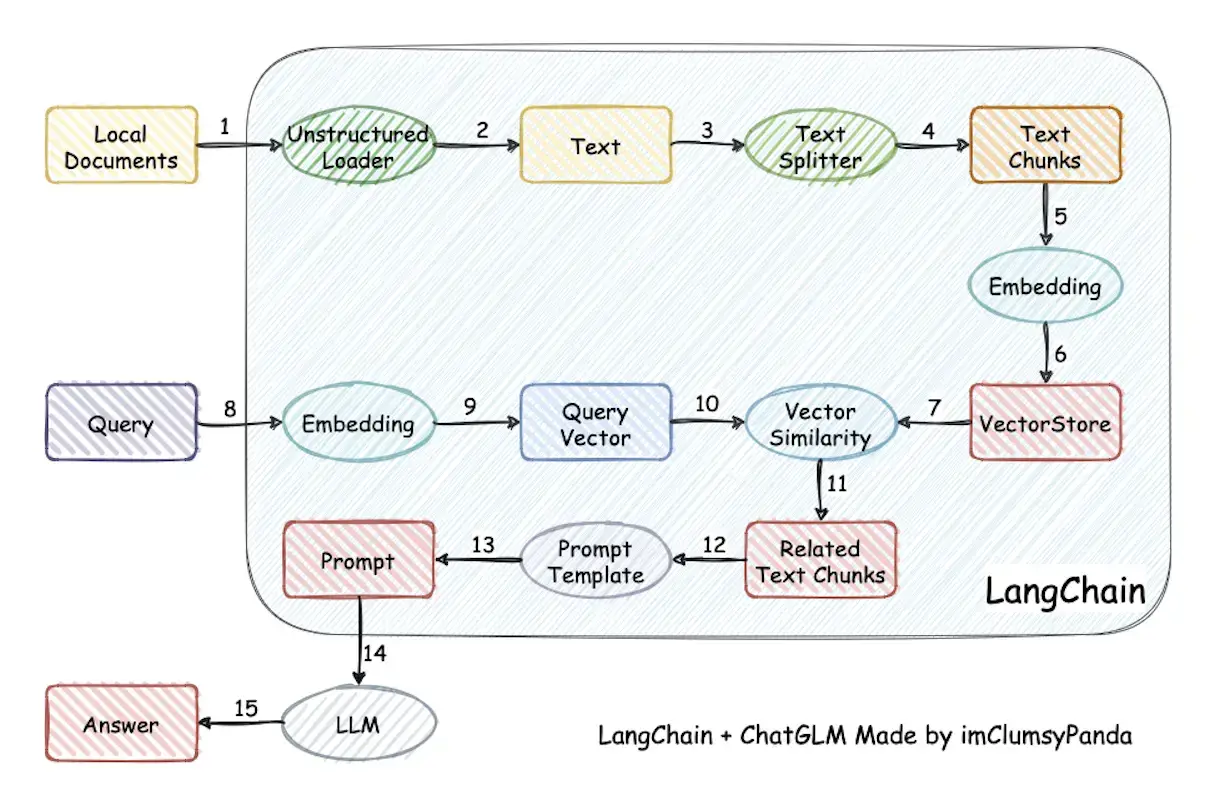
再从从文档处理角度来看,实现流程如下:
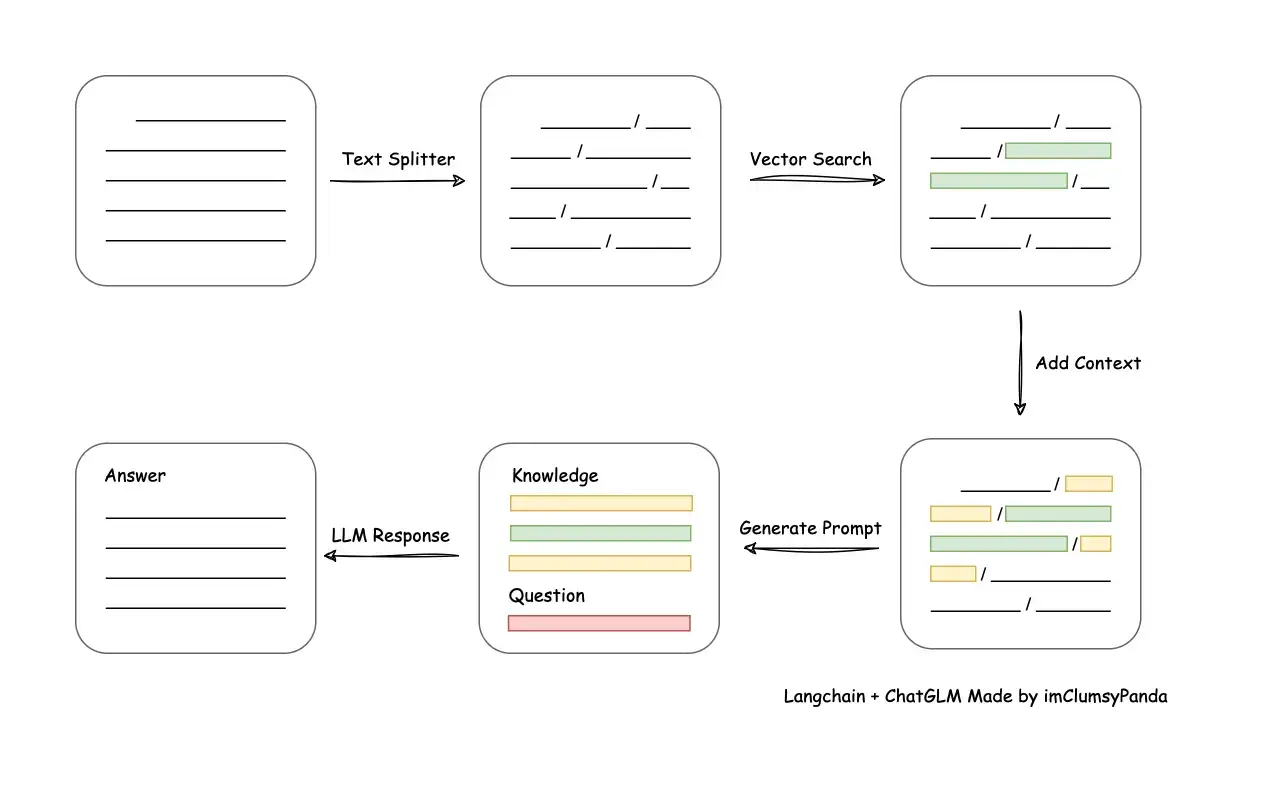
这里需要注意,本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。
部署要求
软件要求:
操作系统
- Linux Ubuntu 22.04.5 kernel version 6.7
其他系统可能出现系统兼容性问题。
最低要求
该要求仅针对标准模式,轻量模式使用在线模型,不需要安装torch等库,也不需要显卡即可运行。
- Python 版本: >= 3.8(很不稳定), < 3.12
- CUDA 版本: >= 12.1
推荐要求
开发者在以下环境下进行代码调试,在该环境下能够避免最多环境问题。
- Python 版本 == 3.11.7
- CUDA 版本: == 12.1
硬件要求:
如果想要顺利在GPU运行本地模型的 FP16 版本,你至少需要以下的硬件配置,来保证在我们框架下能够实现 稳定连续对话
- ChatGLM3-6B & LLaMA-7B-Chat 等 7B模型 最低显存要求: 14GB 推荐显卡: RTX 4080
- Qwen-14B-Chat 等 14B模型 最低显存要求: 30GB 推荐显卡: V100
- Yi-34B-Chat 等 34B模型 最低显存要求: 69GB 推荐显卡: A100
- Qwen-72B-Chat 等 72B模型 最低显存要求: 145GB 推荐显卡:多卡 A100 以上
部署 Langchain-Chatchat
Docker 部署
[链接登录后可见][链接登录后可见]
开发组为开发者们提供了一键部署的 docker 镜像文件懒人包。开发者们可以在 AutoDL 平台和 Docker 平台一键部署。
代码登录后可见
- 该版本镜像大小 50.1GB,使用 v0.2.10,以 nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 为基础镜像
- 该版本为正常版本,非轻量化版本
- 该版本内置并默认启用一个 Embedding 模型:bge-large-zh-v1.5,内置并默认启用 ChatGLM3-6B
- 该版本目标为方便一键部署使用,请确保您已经在 Linux 发行版上安装了 NVIDIA 驱动程序
- 请注意,您不需要在主机系统上安装 CUDA 工具包,但需要安装 NVIDIA Driver 以及 NVIDIA Container Toolkit,请参考安装指南
本地部署方案
代码登录后可见
代码登录后可见
- 模型下,如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
代码登录后可见
- 初始化知识库,当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库
代码登录后可见
- 一键启动,一键启动脚本 startup.py, 一键启动所有 Fastchat 服务、API 服务、WebUI 服务
代码登录后可见
启动界面
正常启动后,会有两种使用界面,一种是
Web UI
Web UI 知识库管理页面
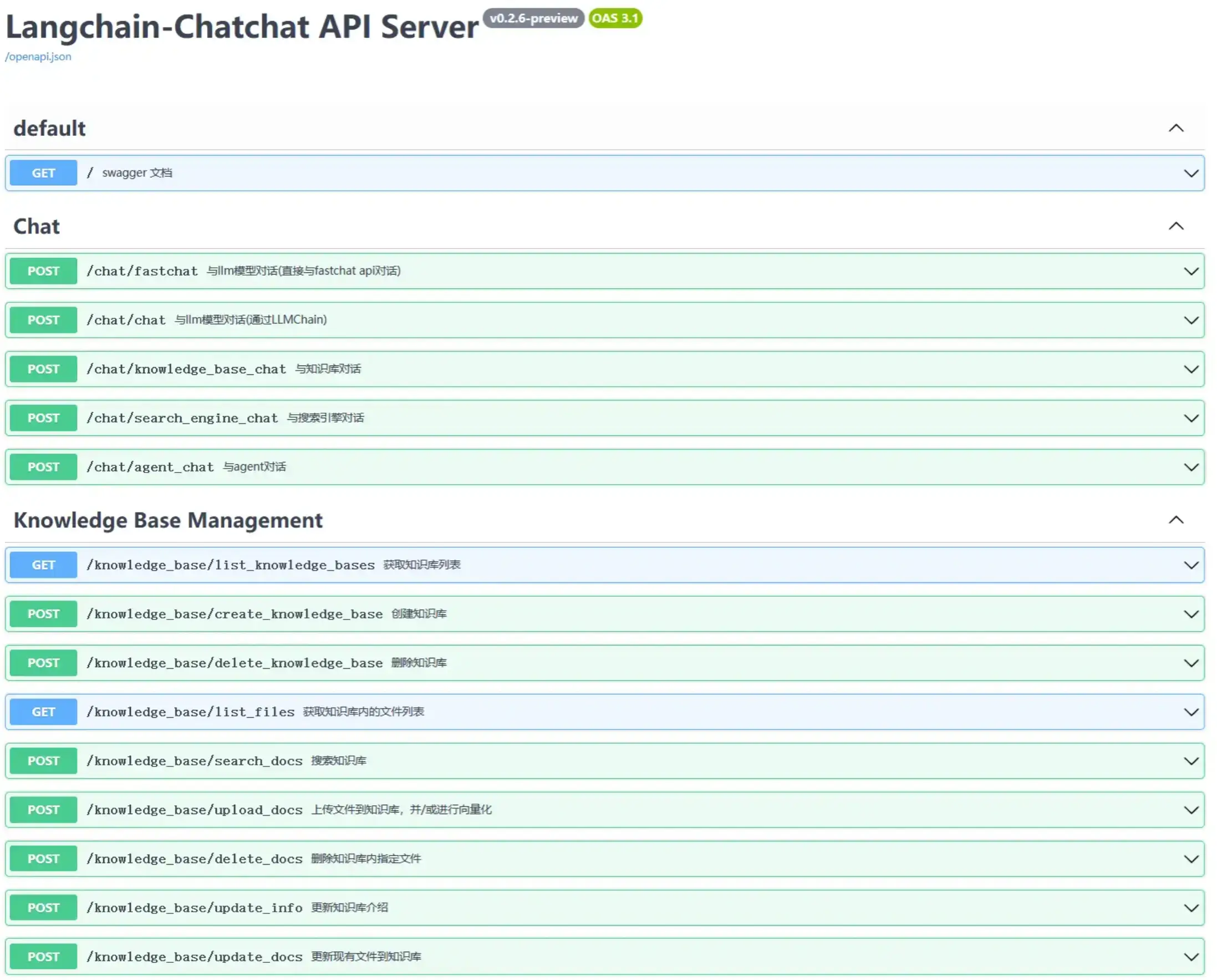
 另一种使用方式是API,以下是查看提供的API。
另一种使用方式是API,以下是查看提供的API。
最轻模式
以上的部署方式是需要显卡的,对于我们这些没卡的一族来说,就很尴尬。但是项目很贴心,提供一个lite模式,该模式的配置方式与常规模式相同,但无需安装 torch 等重依赖,通过在线API实现 LLM 和 Ebeddings 相关功能,适合没有显卡的电脑使用。
代码登录后可见
该模式支持的在线 Embeddings 包括:
- 智谱AI
- MiniMax
- 百度千帆
- 阿里云通义千问
在 model_config.py 中 将 LLM_MODELS 和 EMBEDDING_MODEL 设置为可用的在线 API 名称即可