解压安装包
代码登录后可见
代码登录后可见
service配置文件
代码登录后可见
重启服务
代码登录后可见
安装Grafana
Ubuntu22
更新系统包
代码登录后可见
安装所需的依赖
代码登录后可见
添加Grafana的APT存储库
代码登录后可见
代码登录后可见
更新APT包列表并安装Grafana
代码登录后可见
启动并启用Grafana服务
代码登录后可见
访问Grafana
代码登录后可见
默认的登录用户名和密码都是 代码登录后可见。第一次登录时,系统会提示你修改密码。
配置防火墙(可选)
如果你的系统启用了防火墙(例如 代码登录后可见),你需要允许3000端口的访问:
代码登录后可见
Centos7
添加Grafana的YUM存储库
代码登录后可见
更新YUM缓存并安装Grafana
代码登录后可见
启动并启用Grafana服务
代码登录后可见
配置防火墙
如果你启用了防火墙,需要允许3000端口的访问(Grafana默认运行在3000端口):
代码登录后可见
访问Grafana
打开浏览器,访问以下URL:
代码登录后可见
使用阿里源加速
如果你在中国大陆,可以使用阿里源来加速安装包的下载。你可以修改Grafana的YUM存储库为阿里云镜像:
代码登录后可见
Grafana配置为中文
代码登录后可见
将default_language = en-US改为 zh-Hans即可,存在部分翻译不完全
代码登录后可见
重启服务
代码登录后可见
使用
grafana 上配置 loki 数据源
 在数据源列表中选择 Loki,配置 Loki 源地址:
在数据源列表中选择 Loki,配置 Loki 源地址:
源地址配置 [链接登录后可见] 即可,保存。
保存完成后,切换到 grafana 左侧区域的 Explore,即可进入到 Loki 的页面。
然后我们点击 Log labels 就可以把当前系统采集的日志标签给显示出来,可以根据这些标签进行日志的过滤查询:
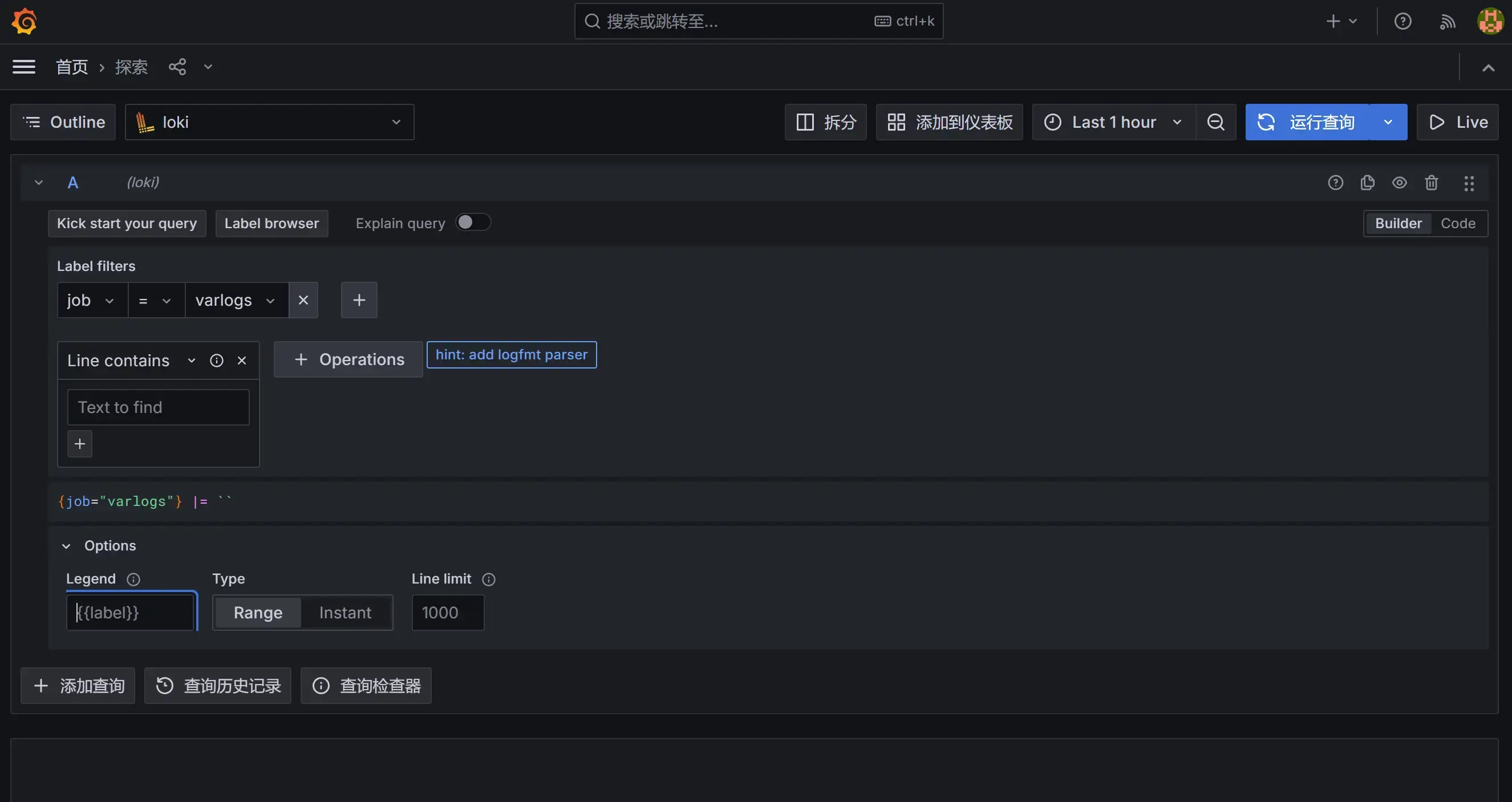
比如我们这里选择 varlogs,就会把该文件下面的日志过滤展示出来,不过由于时区的问题,可能还需要设置下时间才可以看到数据:
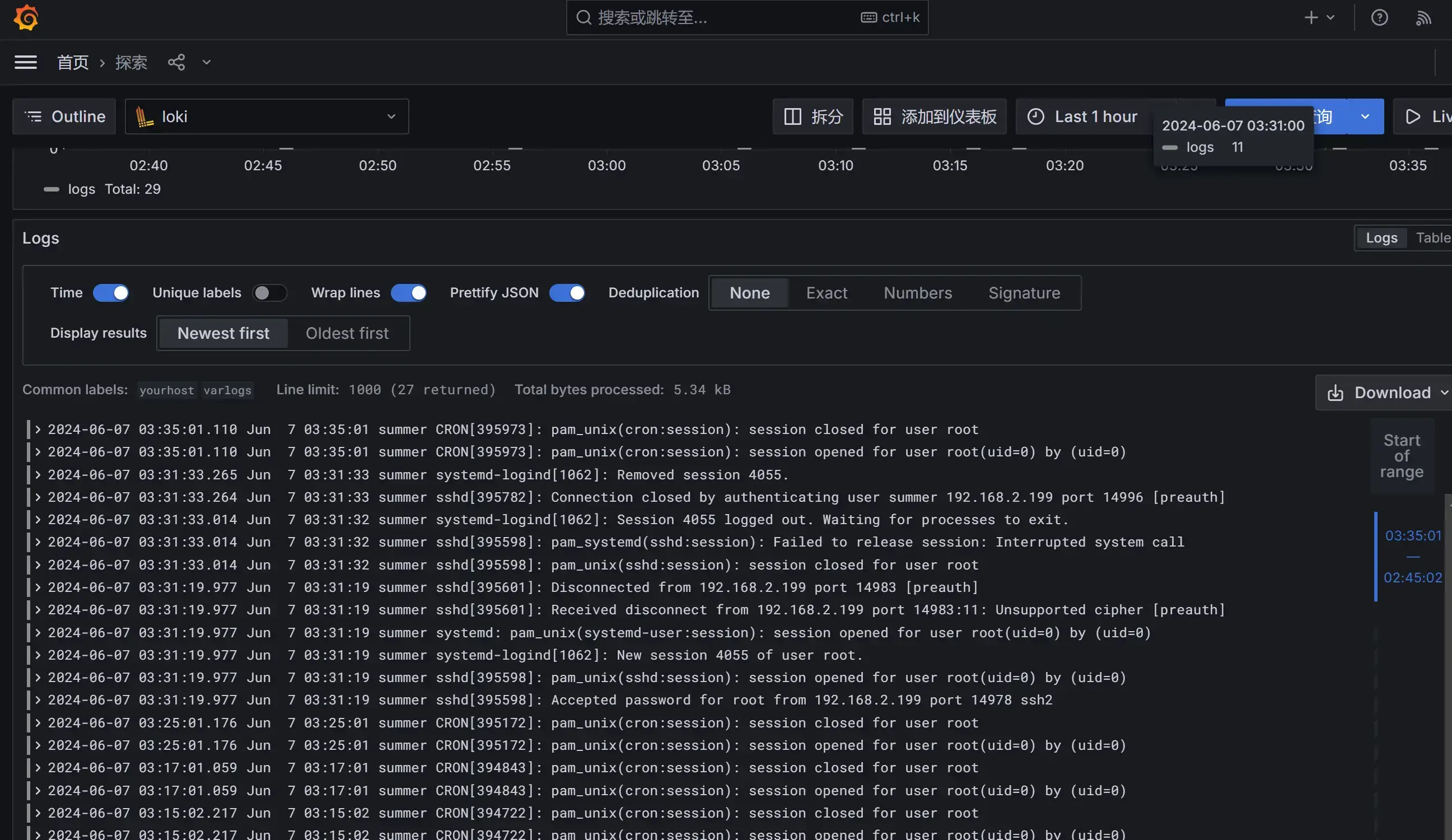
在 grafana explore 上配置查看日志
代码登录后可见
算 qps rate({job=”message”} |=”kubelet” [1m])
只索引标签
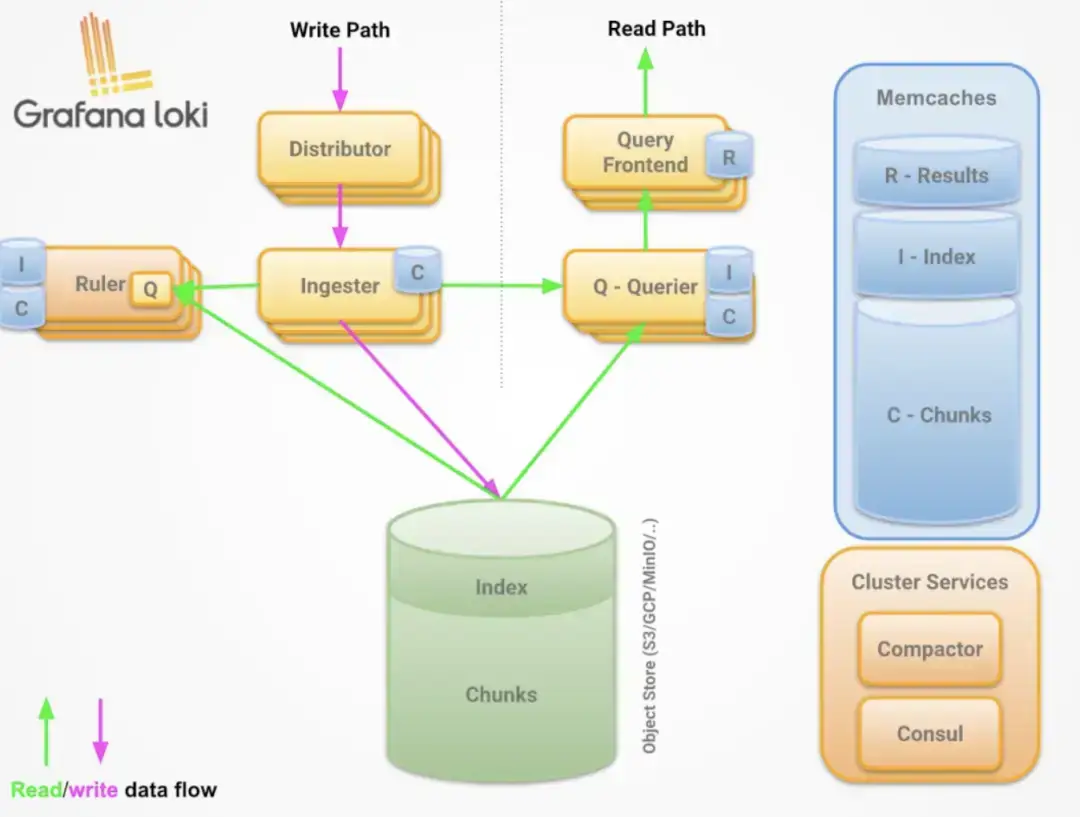
之前多次提到 loki 和 es 最大的不同是 loki 只对标签进行索引而不对内容索引。下面我们举例来看下。
静态标签匹配模式
以简单的 promtail 配置举例:
代码登录后可见
配置解读:
- 上面这段配置代表启动一个日志采集任务
- 这个任务有 1 个固定标签 job=”syslog”
- 采集日志路径为 /var/log/messages,会以一个名为 filename 的固定标签
- 在 promtail 的 web 页面上可以看到类似 prometheus 的 target 信息页面
可以和使用 Prometheus 一样的标签匹配语句进行查询。
{job=“syslog”}:
代码登录后可见
如果我们配置了两个 job,则可以使用job=~”apachesyslog”进行多 job 匹配;同时也支持正则和正则非匹配。
标签匹配模式的特点
原理如下:
- 和 prometheus 一致,相同标签对应的是一个流 prometheus 处理 series 的模式
- prometheus 中标签一致对应的同一个 hash 值和 refid(正整数递增的 id),也就是同一个 series
- 时序数据不断的 append 追加到这个 memseries 中
- 当有任意标签发生变化时会产生新的 hash 值和 refid,对应新的 series
loki 处理日志的模式和 prometheus 一致,loki 一组标签值会生成一个 stream。日志随着时间的递增会追加到这个 stream 中,最后压缩为 chunk。当有任意标签发生变化时会产生新的 hash 值,对应新的 stream。
查询过程
- 所以 loki 先根据标签算出 hash 值在倒排索引中找到对应的 chunk?
- 然后再根据查询语句中的关键词等进行过滤,这样能大大的提速
- 因为这种根据标签算哈希在倒排中查找 id,对应找到存储的块在 prometheus 中已经被验证过了
- 属于开销低
- 速度快
动态标签和高基数
所以有了上述知识,那么就得谈谈动态标签的问题了。
两个概念:
- 何为动态标签:说白了就是标签的 value 不固定
- 何为高基数标签:说白了就是标签的 value 可能性太多了,达到 10 万,100 万甚至更多
比如 apache 的 access 日志:
代码登录后可见
在 Promtail 中使用 regex 想要匹配 action 和 status_code 两个标签:
代码登录后可见
那么对应 action=get/post 和 status_code=200/400 则对应 4 个流:
代码登录后可见
那四个日志行将变成四个单独的流,并开始填充四个单独的块。
如果出现另一个独特的标签组合(例如 status_code =“500”),则会创建另一个新流。
高基数问题
就像上面,如果给 ip 设置一个标签,现在想象一下,如果您为设置了标签 ip,来自用户的每个不同的 ip 请求不仅成为唯一的流。可以快速生成成千上万的流,这是高基数,这可以杀死 Loki。
如果字段没有被当做标签被索引,会不会查询很慢,Loki 的超级能力是将查询分解为小块并并行分发,以便您可以在短时间内查询大量日志数据。
全文索引问题
大索引既复杂又昂贵。通常,日志数据的全文索引的大小等于或大于日志数据本身的大小。
要查询日志数据,需要加载此索引,并且为了提高性能,它可能应该在内存中。这很难扩展,并且随着您摄入更多日志,索引会迅速变大。
Loki 的索引通常比摄取的日志量小一个数量级,索引的增长非常缓慢。
加速查询没标签字段:以上边提到的 ip 字段为例 - 使用过滤器表达式查询。
代码登录后可见
loki 查询时的分片(按时间范围分段 grep):
- Loki 将把查询分解成较小的分片,并为与标签匹配的流打开每个区块,并开始寻找该 IP 地址。
- 这些分片的大小和并行化的数量是可配置的,并取决于您提供的资源
- 如果需要,您可以将分片间隔配置为 5m,部署 20 个查询器,并在几秒钟内处理千兆字节的日志
- 或者,您可以发疯并设置 200 个查询器并处理 TB 的日志!
两种索引模式对比:
- es 的大索引,不管你查不查询,他都必须时刻存在。比如长时间占用过多的内存
- loki 的逻辑是查询时再启动多个分段并行查询
日志量少时少加标签:
- 因为每多加载一个 chunk 就有额外的开销
- 举例,如果该查询是 {app=”loki”,level!=”debug”}
- 在没加 level 标签的情况下只需加载一个 chunk 即 app=“loki” 的标签
- 如果加了 level 的情况,则需要把 level=info,warn,error,critical 5 个 chunk 都加载再查询
需要标签时再去添加:
- 当 chunk_target_size=1MB 时代表 以 1MB 的压缩大小来切割块
- 对应的原始日志大小在 5MB-10MB,如果日志在 max_chunk_age 时间内能达到 10MB,考虑添加标签
日志应当按时间递增:
- 这个问题和 tsdb 中处理旧数据是一样的道理
- 目前 loki 为了性能考虑直接拒绝掉旧数据
独立日志采集
要使用 Grafana Loki 来收集和监控其他服务器上的特定日志文件(例如 代码登录后可见),你可以按照以下步骤进行配置。这里我们将使用 Promtail 作为日志收集器。
假设你已经在你的主服务器上安装了 Loki 并运行。
在被监控服务器上安装 Promtail
在每个被监控的服务器上安装 Promtail:
代码登录后可见
创建一个 Promtail 配置文件 代码登录后可见。以下是一个示例配置文件,专门用于采集 代码登录后可见 文件:
代码登录后可见
请根据实际情况修改 代码登录后可见 为你的 Loki 服务器的 IP 地址。
使用以下命令启动 Promtail:
代码登录后可见
为了确保 Promtail 在系统重启后自动启动,可以创建一个 systemd 服务:
代码登录后可见
在 Grafana 中配置 Loki 数据源
打开 Grafana Web 界面,登录后进入设置(齿轮图标),选择 “Data Sources”(数据源),然后点击 “Add data source”(添加数据源)。
在数据源列表中选择 “Loki”。
在 URL 字段中输入你的 Loki 服务器地址,例如 代码登录后可见。完成后点击 “Save & Test”(保存并测试)。
创建仪表板
在 Grafana 中点击 “+” 图标,然后选择 “Dashboard” 来创建一个新的仪表板。
在新仪表板中,添加一个新的面板。选择 Loki 作为数据源,然后输入查询语句,例如:
代码登录后可见
根据需要配置面板的显示样式、时间范围等,完成后保存仪表板。
定时采集日志
Promtail 和 Loki 的设计目的是用于实时收集和监控日志。如果你希望每天定时获取一次日志,可能需要采取不同的方法,比如使用定时任务(cron job)来实现这一功能。以下是如何在 CentOS 7 上使用 cron job 定时获取日志并将其推送到 Loki 的步骤。
创建日志收集脚本
首先,创建一个脚本,该脚本会在指定时间收集日志并推送到 Loki。
代码登录后可见
在脚本中添加以下内容:
代码登录后可见
请确保将 代码登录后可见 替换为你的 Loki 服务器的实际 IP 地址。
保存并关闭文件,然后为脚本赋予执行权限:
代码登录后可见
创建 Cron Job
编辑 cron 配置文件来创建一个定时任务,每天12点执行日志收集脚本。
代码登录后可见
添加以下行:
代码登录后可见
这行命令会每天中午12点执行一次 代码登录后可见 脚本。
如果你计划每天定时推送一次日志,而不是实时监控,那么应该删除掉 Promtail 的 systemd 服务,因为 Promtail 的设计是用于实时日志收集和监控。
删除 Promtail 的 systemd 服务
代码登录后可见
代码登录后可见
代码登录后可见
在当前的脚本中,推送到 Loki 的日志是追加的,而不是覆盖的。每次运行脚本时,它会将当前日志文件的全部内容发送到 Loki,这意味着每天定时任务会将当时的整个日志文件内容推送一次。
如果你的日志文件是按天滚动的(例如,每天生成一个新的日志文件),那么上述方法没有问题。如果日志文件没有按天滚动,日志内容会每天增长,推送的内容会越来越多。为了避免这种情况,你可以仅推送新增加的日志内容。
修改脚本以仅推送新增日志
可以通过记录上次读取的位置来实现增量推送日志。以下是修改后的脚本,使用一个位置文件来记录上次读取的位置:
编辑或创建 代码登录后可见:
代码登录后可见
添加以下内容并保存:
代码登录后可见
确保将 代码登录后可见 替换为你的 Loki 服务器的实际 IP 地址,并为脚本赋予执行权限:
代码登录后可见
编辑 Cron 配置文件来创建一个定时任务,每天12点执行日志收集脚本:
代码登录后可见
添加以下行:
代码登录后可见
通过这种方式,脚本将每天只推送新增的日志内容,而不是整个日志文件的内容。这将减少推送的数据量,并确保日志数据在 Loki 中的连续性。如果发送日志的机器默认只保留7天的日志,Loki 将能够正确地保留并展示这些日志
处理日志文件轮转
Promtail会自动检测到日志文件的轮转,并处理新的日志文件。这意味着当你的程序将日志打包存放到别的地方并创建一个新的日志文件时,Promtail会继续从新的日志文件中读取内容并推送到Loki。
配置Promtail以处理文件轮转
创建或编辑Promtail的配置文件 代码登录后可见,使其能够处理日志文件轮转:
代码登录后可见
请确保将 代码登录后可见 替换为你的 Loki 服务器的实际 IP 地址。
创建启动 Promtail 的脚本
创建一个脚本来启动 Promtail:
代码登录后可见
添加以下内容并保存:
代码登录后可见
确保为脚本赋予执行权限:
代码登录后可见
使用 Cron Job 定时启动 Promtail
编辑 Cron 配置文件来创建一个定时任务,每天启动 Promtail:
代码登录后可见
添加以下行:
代码登录后可见
这行命令会每天中午12点执行一次 代码登录后可见 脚本。
通过这些步骤,你可以确保在日志文件轮转后,Promtail仍然能够连续收集并推送新的日志内容到 Loki。Promtail的文件轮转处理功能可以确保日志数据的连续性,即使在日志文件被重命名或移动的情况下。
日志存放
在Loki中,日志数据存储的位置和删除方式取决于你如何配置了Loki的存储后端。Loki支持多种存储后端,如本地文件系统、对象存储(如S3、GCS)等
如果你配置Loki使用本地文件系统存储日志数据,通常配置文件中会指定一个目录。例如:
代码登录后可见
在这种情况下,日志数据存储在 代码登录后可见 和 代码登录后可见 目录下。
如果你使用对象存储(如AWS S3或GCS),日志数据将存储在指定的桶中。配置示例如下:
代码登录后可见
手动删除日志数据
手动删除某个节点的日志文件涉及删除存储后端的相关数据。以下是如何操作的说明:
本地文件系统
为了安全删除文件,首先停止Loki服务:
代码登录后可见
查找并删除相关的日志文件。例如,删除特定时间段或节点的日志文件:
代码登录后可见
删除文件后,重新启动Loki服务:
代码登录后可见
对象存储
使用对象存储服务提供的管理工具或API来删除特定日志文件。例如,使用AWS CLI删除S3桶中的对象:
代码登录后可见
注意
- 数据一致性:手动删除日志文件可能会导致数据不一致。如果需要定期删除日志数据,建议使用Loki的Retention机制。
- 保留策略:配置Loki的保留策略,以自动管理日志数据的生命周期。例如,配置一个7天的保留策略:
代码登录后可见
如果你要查找loki的日志文件存放路径,请按以下操作
查找Loki的配置文件
Loki的配置文件通常位于以下路径之一:
查看配置文件中的存储设置
打开Loki的配置文件并查看 代码登录后可见部分。
识别存储路径
在配置文件的 代码登录后可见部分,你可以看到日志文件的存储位置:
反向代理
参考教程:[链接登录后可见]
⚠️Nginx Proxy Manager(以下简称NPM)会用到80、443端口,所以本机不能占用(比如原来就有Nginx)
互联网使用请确保完成了域名解析